






芯片资讯
热点资讯
- iPhone 16 配备 8GB 内存,支持 Wi-Fi 6E
- 德州仪器(TI)代理商还剩哪些?从分散到集权的博弈,及艾睿受限后的破局之路
- 全球GPU呈现“一超一强”竞争格局
- 兆易创新拟募资43亿元 设计和研发DRAM芯片
- 中国 Chiplet 芯粒产业全景整理:设计公司、封装专利、技术工艺及相关企业
- 思瑞浦 3PEAK 推出 I3C 电平转换芯片 TPT29606
- 安世半导体遇 “双向围堵”:荷兰冻 147 亿资产,中国限在华器件出口
- 南昌凯迅光电股份有限公司辅导备案报告公示
- 电子工程师必备:Marvell(美满电子)产品线与料号解码,从型号到应用
- 纳芯微电子获数千万元B轮融资 聚焦传感器与数字隔离芯片
- 发布日期:2024-01-05 12:55 点击次数:199
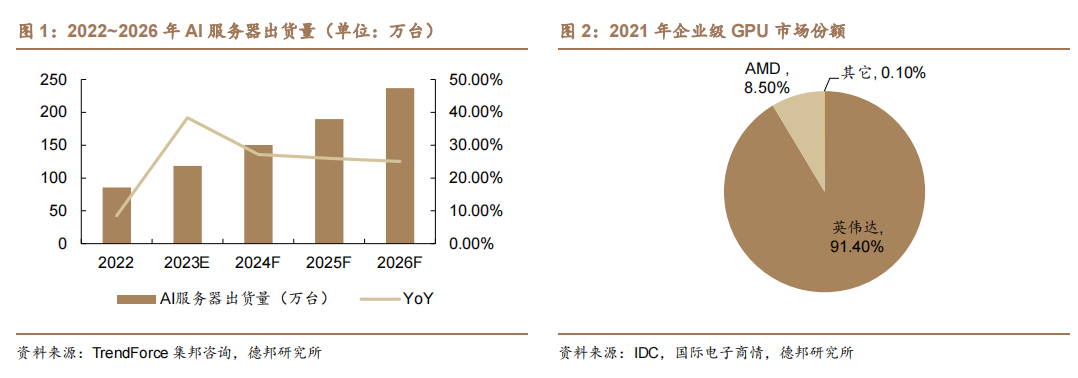
AI 服务器发展迅速,GPU 环节被英伟达与 AMD 所占据。AIGC 的发展带动AI 服务器迅速增长,TrendForce 集邦咨询预计 23 年 AI 服务器出货量约 120 万台,同比+38.4%,占整体服务器出货量的比约为9%,2022~2026 年 AI 服务器出货量 CAGR 将达 22%,而 AI 芯片 2023 年出货量将成长 46%。GPU 作为数据并行处理的核心,是 AI 服务器的核心增量。
本文来自“行业专题:GPU龙头产品迭代不断,产业链各环节持续催化”,全球GPU呈现“一超一强”的竞争格局,根据 IDC 数据,2021 英伟达在企业级 GPU 市场中占比 91.4%,AMD 占比 8.5%。
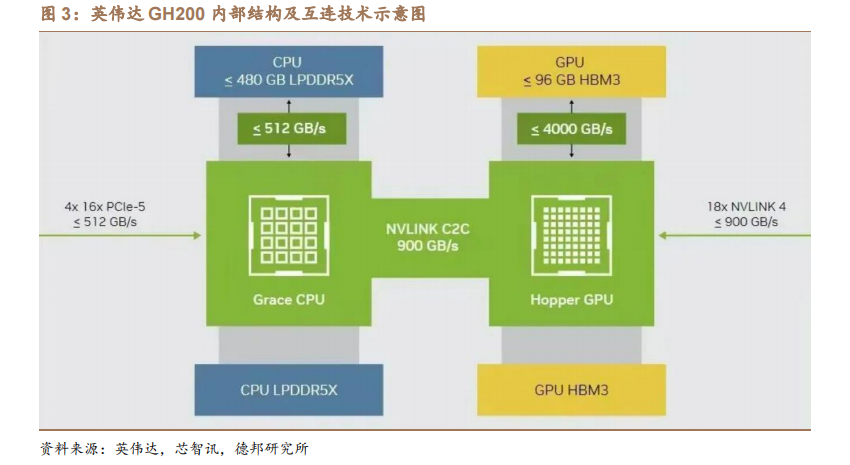
目前英伟达产品 DGX GH200 已发布,互连技术强大,算力进一步升级。5月 29 日,英伟达在其发布会上,正式发布最新的 GH200 Grace Hopper 超级芯片,以及拥有 256 个 GH200 超级芯片的 NVIDIA DGX GH200 超级计算机。
GH200超级芯片内部集成了 Grace CPU 和 H100 GPU,晶体管数量达 2000 亿个。其借助 NVIDIA NVLink-C2C 芯片互连,将英伟达 Grace CPU 与英伟达 H100 TensorCore GPU 整合。与 PCIe Gen5 技术相比,其 GPU 和 CPU 之间的带宽将提高 7倍,并将互连功耗减少至 1/5 以下。同时,DGX GH200 的 AI 性能算力将达到1exaFLOPS。
英伟达产品 DGX GH200 共享内存大幅提升,突破内存瓶颈。DGX GH200系统将 256 个 GH200 超级芯片与 144TB 的共享内存进行连接,进一步提高系统协同性。与 DGX H100 相比,DGX GH200 的共享内存提升约 230 倍。凭借强大的共享内存,GH200 能够显著改善受 GPU 内存大小瓶颈影响的 AI 和 HPC 应用程序的性能。而在具有 tb 级嵌入式表的深度学习推荐模型(DLRM)、tb 级图神经网络训练模型或大型数据分析工作负载中,使用 DGX GH200 可将速度提高4到7倍。
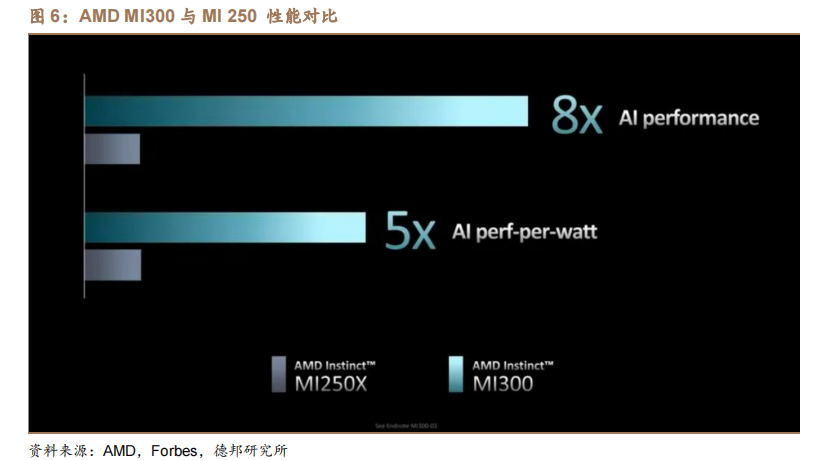
而 AMD 在美国时间 2023 年 6 月 13 日,推出其新款 AI 芯片 MI300 系列,两款芯片分别为 MI300A 与 MI300X,分别集成 1460、1530 亿个晶体管。MI300A内含 13 个小芯片,总共集成 1460 亿个晶体管,其内部包含 24 个 Zen 4 CPU 核心、1 个 CDNA 3 图形引擎和 128GB HBM3 内存;而 MI300X 是针对大预言模型的优化版本,其内存达 192GB,内存带宽为 5.2TB/s,Infinity Fabric 带宽为896GB/s,晶体管达 1530 亿个。AMD 表示,与上代 MI 250 相比,MI300 的 AI性能和每瓦性能分别为 MI250 的 8 倍和 5 倍。
应用先进封装 Chiplet 技术与 HBM3,工艺技术驱动产品升级。在以往 CPU、GPU 设计中,AMD 常利用其先进的封装堆叠技术,集成多个小核心,从而实现整体性能的提升。根据芯智讯,MI300 由 13 个小芯片整合而成,其中其计算部分由 9 个基于台积电 5nm 工艺制程的小芯片组成,这些小芯片包括了 CPU 和 GPU内核。3D 堆叠设计极大提升了 MI 300 的性能与数据吞吐量。同时,MI300 两侧排列着 8 个合计 128GB 的 HBM3 芯片,满足其海量且高速的数据存储需求。

AI 大模型等 AIGC 产业的升级离不开算力的底层支持, 芯片采购平台使得 GPU 等大算力芯片性能持续提升,带来产业链各环节增量。以英伟达 DGX H100 为例,其在GPU、互连技术、智能网卡、内存条、硬盘等结构上均较普通服务器有较大提升,同时其 PCB 的面积需求量与性能要求亦高于普通服务器。

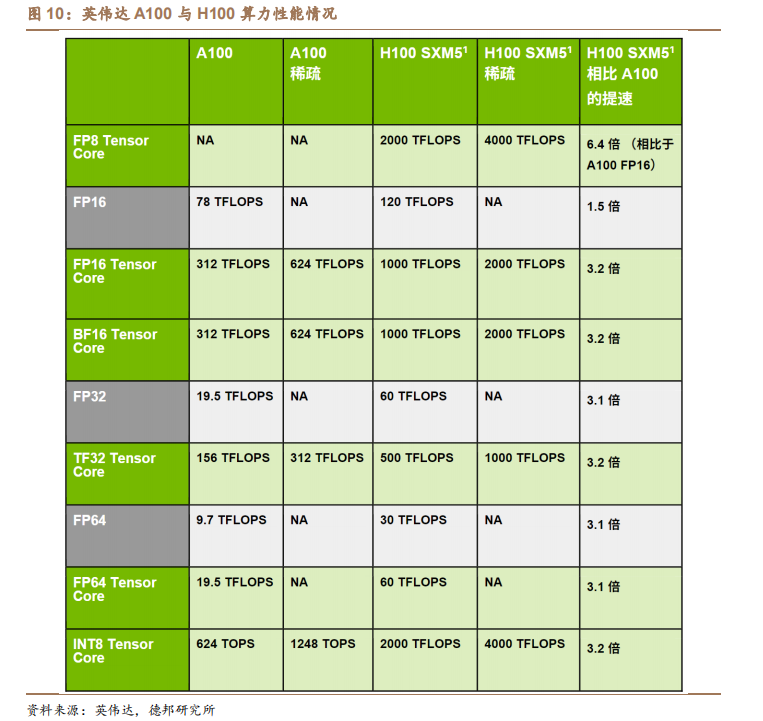
(1)GPU:量价齐升,产业链最大增量。一般的普通服务器仅会配备单卡或双卡,而 AI 服务器由于需要承担大量的计算,一般配置四块或以上的 GPU。且AI大模型在训练与推理时的计算量巨大,中低端的GPU无法满足其运算需求。如在英伟达 DGX H100 中,其配备 8 个 NVIDIA H100 GPU,总 GPU 显存高达640GB;每个GPU配备18个NVIDIA NVLink,GPU之间的双向带宽高达900GB/s。若以每个 NVIDIA H100 GPU 单价 4 万美元测算,DGX H100 的 GPU 价值量为32 万美元,为 AI 服务器中的最大增量。
(2)硬盘:AI 服务器 NAND 数据存储需求提升 3 倍。AI 服务器的高吞吐量及训练模型的高参数量级亦推升 NAND 数据存储需求。美光估计,AI 服务器中NAND 需求量是传统服务器的 3 倍。一台 DGX H100 中,SSD 的存储容量达 30TB。
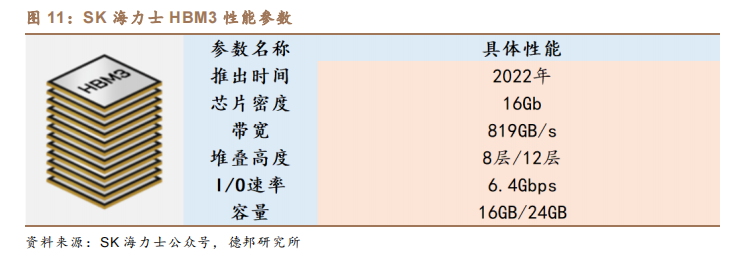
(3)内存:AI 服务器 DRAM 数据存储需求提升 8 倍,HBM 需求快速提升。以 HBM 为主要代表的存算一体芯片能够通过 2.5D/3D 堆叠,将多个存储芯片与处理器芯片封装在一起,克服单一封装内带宽的限制、增加带宽、扩展内存容量、并减少数据存储的延迟。根据公众号全球 SSD,三星 2021 年 2 月与 AMD 合作开发 HBM-PIM,将内存和 AI 处理器合而为一,在 CPU 和 GPU 安装 HBM-PIM,显著提高服务器运算速度。2023 年开年后,三星高带宽存储器(HBM)订单快速增加。SK 海力士亦在 2021 年 10 月成功开发出 HBM3,并于 2022 年 6 月开始量产,在 2022 年第三季度向英伟达进行供货。同时,美光估计,AI 服务器中 DRAM需求量是传统服务器的 8 倍。如在一台 DGX H100 中,内存容量达 2TB。
(4)PCB:AI 服务器 PCB 明确受益 AI 算力提升。目前普通服务器需要 6-16层板和封装基板,而 AI 服务器等高端服务器主板层数则达 16 层以上,背板层数超过 20 层。且除 GPU 外,服务器中主板、电源背板、硬盘背板、网卡、Riser卡等核心部分均需使用 PCB 板进行数据传输。服务器出货量的增加将推动 PCB需求量的提升。

(5)先进封装:高制程芯片设计成本与制造成本均呈现指数型的增长趋势,Chiplet 等先进封装应运而生。随着制程的提升,芯片成本的提升呈现指数型增长。以芯片设计为例,根据 UCIE 白皮书,28nm 制程的芯片设计成本约 0.51 亿美元,但当制程提升至 5nm 时,芯片设计成本则快速升至 5.42 亿美元,成本提升近十倍,先进制程的推进速度愈加缓慢。因此在 HPC 高性能计算领域,Chiplet 的重要性持续提升。
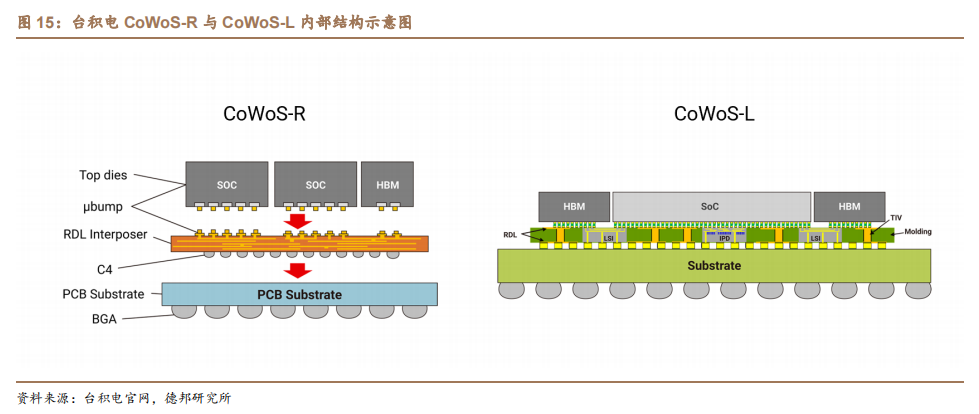
目前,以 CoWoS 为代表的高性能计算先进封装产能紧缺,制约 GPU 产品出货。英伟达 A100、H100 GPU 均采用台积电 CoWoS 先进封装工艺。而根据科创板日报与台湾电子时报,英伟达将原定今年 Q4 的先进封装 CoWoS 产能,改为 Q2-Q4 平均分配生产,订单生产时间较原计划大大提前。目前,台积电 CoWoS封测产能供不应求,部分订单已外溢日月光、矽品与 Amkor、联电等。以 CoWoS 为代表的先进封装技术产能紧缺,已成为制约 GPU 生产的关键环节。
- 全球FPGA芯片市场布局2025-10-08